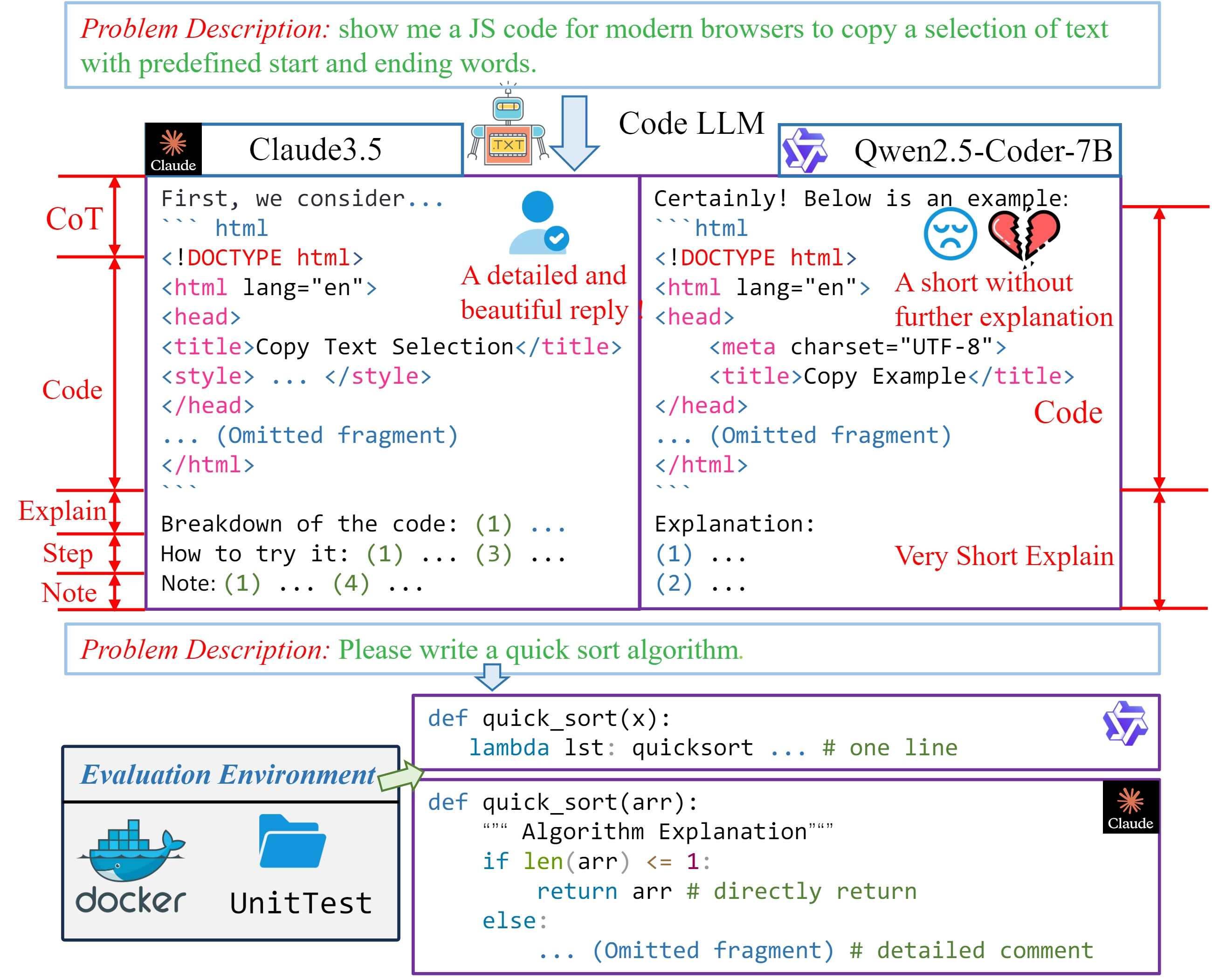
Introduction
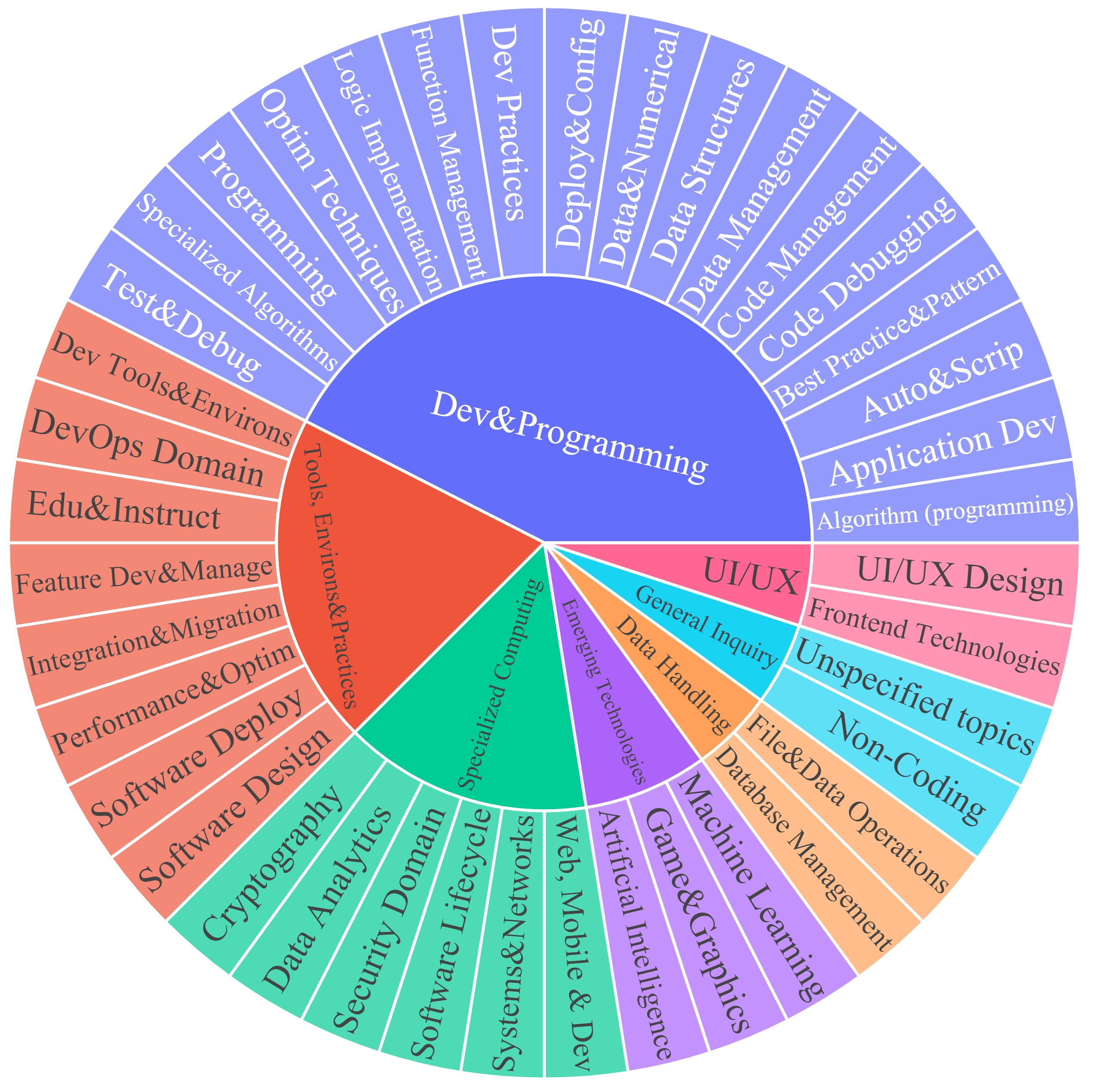
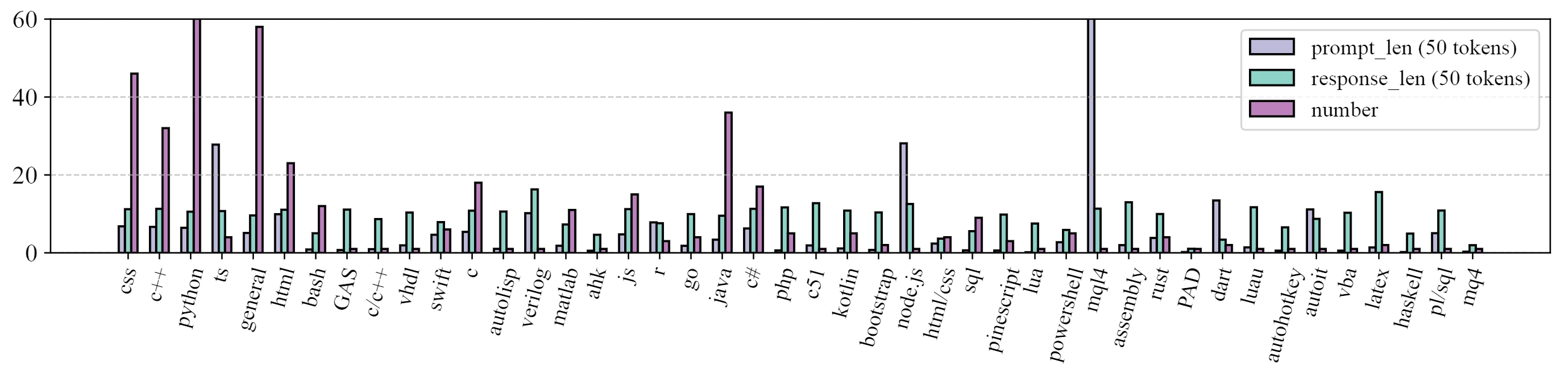
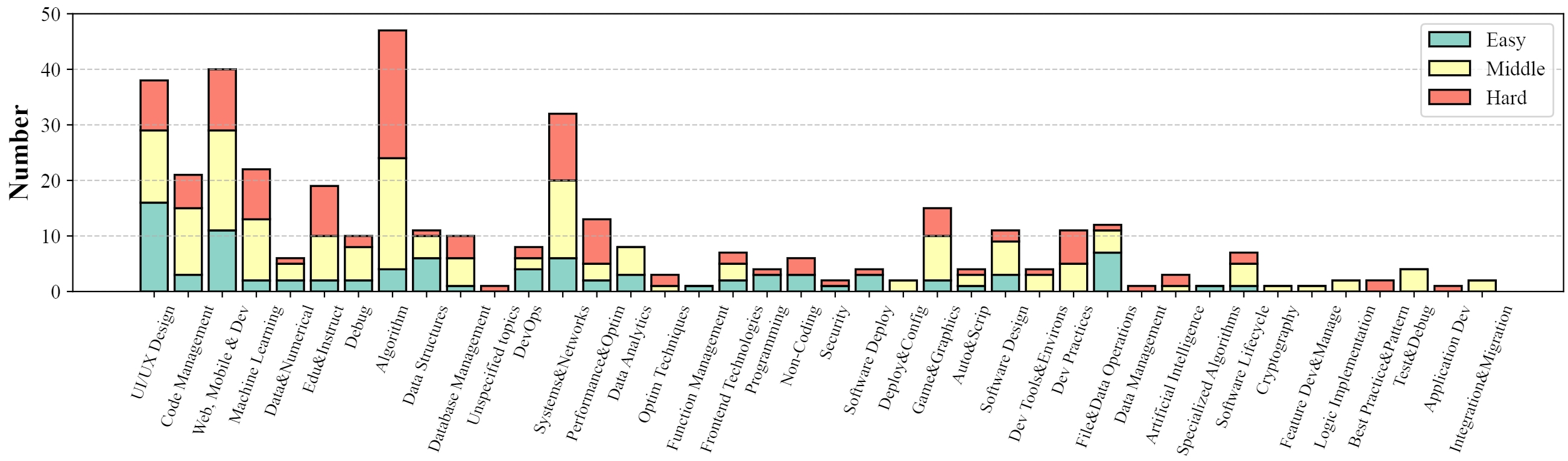
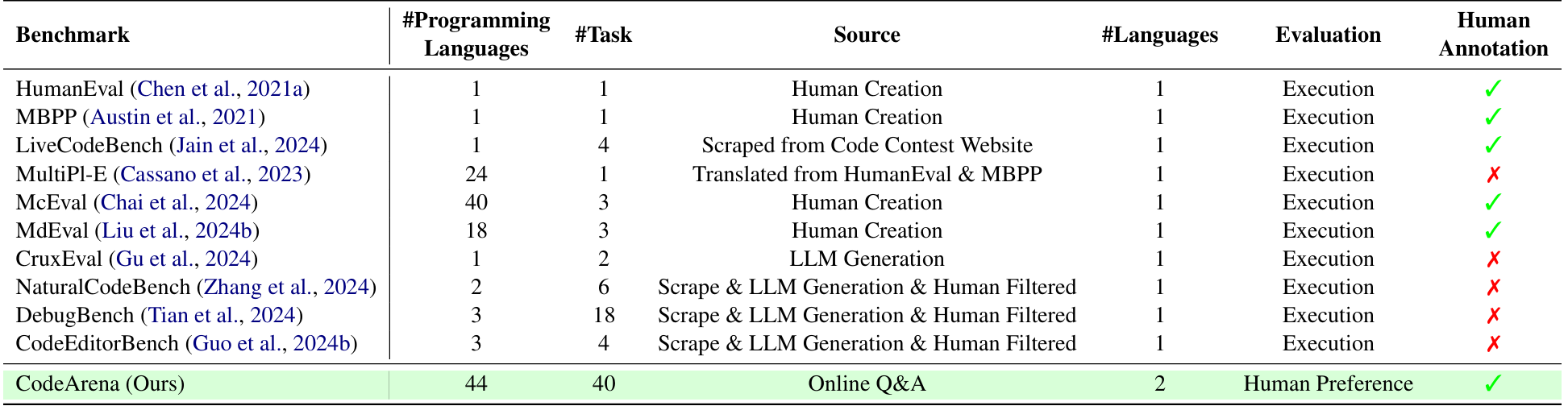
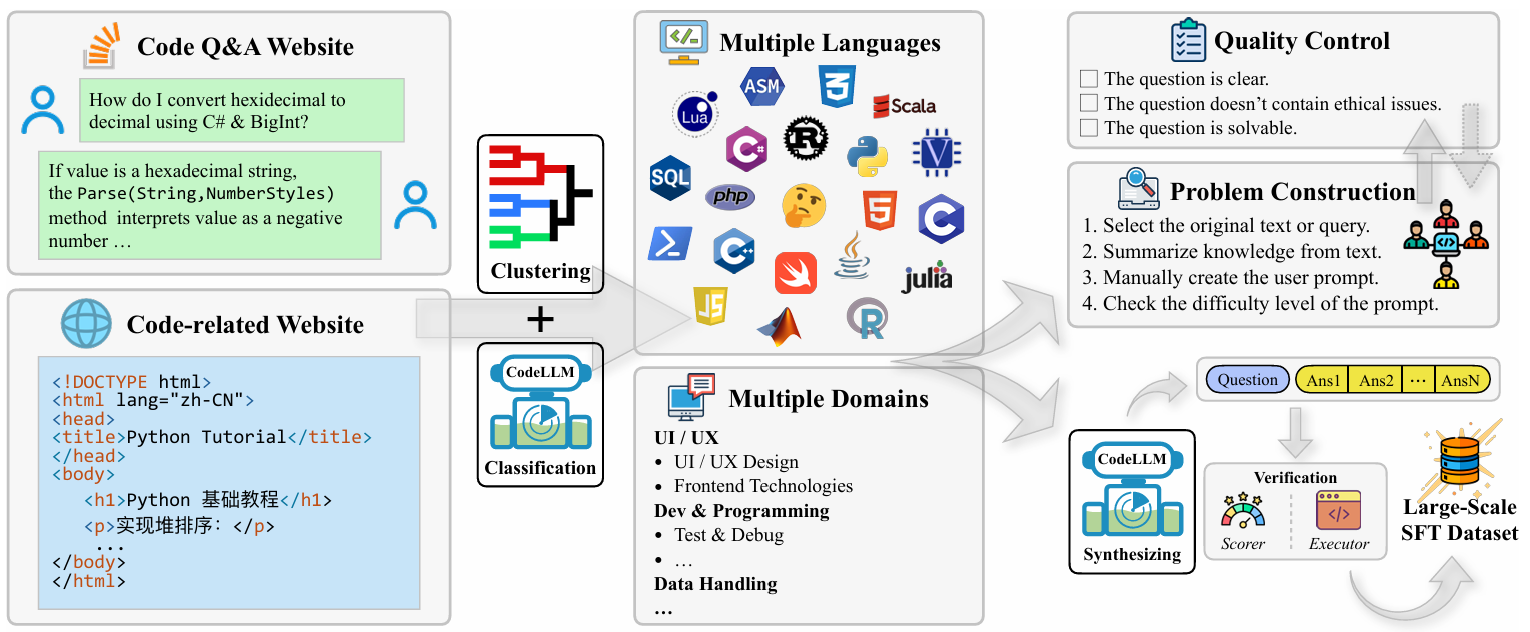
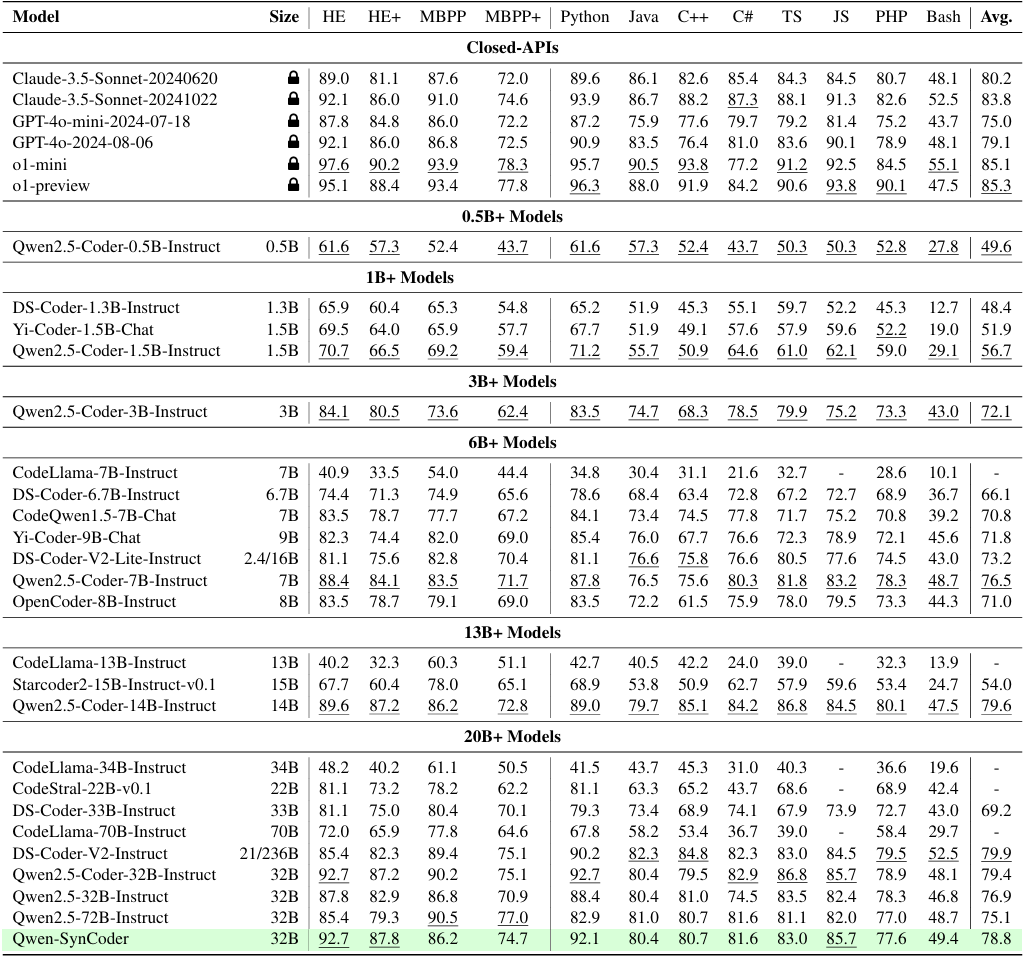
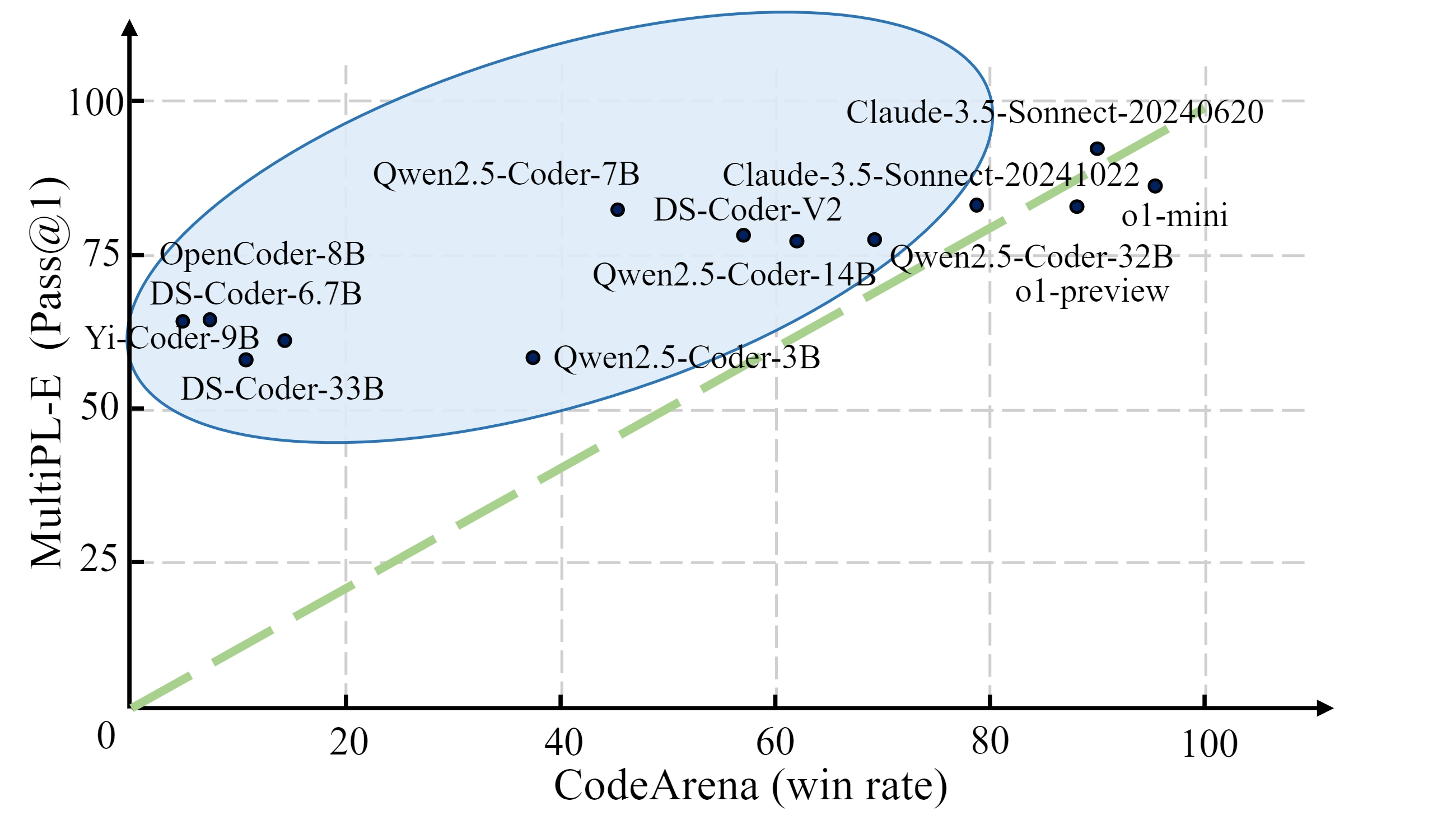
The contributions in this paper are summarized as follows: (1) We propose codearena comprised of 397 manually annotated samples, a comprehensive code evaluation benchmark for evaluating the alignment between the model-generated response and human preference, which covers 40 categories, encompassing 7 major categories and 40 subcategories. (2) We introduce synCode-instruct, the large-scale synthetic code instruction corpora from the website. Based on SynCode-Instruct, an effective coder Qwen2.5-SynCoder is used as a strong baseline for CodeArena. (3) We systematically evaluate 39 LLMs on created CodeArena and create a leaderboard to dynamically update the results. Notably, extensive experiments suggest that CodeArena can effectively measure the alignment between the model-generated response and human preference.